
21 12.2 Internet 101: Understanding How the Internet Works
Learning Objectives
After studying this section you should be able to do the following:
- Describe how the technologies of the Internet combine to answer these questions: What are you looking for? Where is it? And how do we get there?
- Interpret a URL, understand what hosts and domains are, describe how domain registration works, describe cybersquatting, and give examples of conditions that constitute a valid and invalid domain-related trademark dispute.
- Describe certain aspects of the Internet infrastructure that are fault-tolerant and support load balancing.
- Discuss the role of hosts, domains, IP addresses, and the DNS in making the Internet work.
The Internet is a network of networks—millions of them, actually. If the network at your university, your employer, or in your home has Internet access, it connects to an Internet service provider (ISP). Many (but not all) ISPs are big telecommunications companies like Verizon, Comcast, and AT&T. These providers connect to one another, exchanging traffic, and ensuring your messages can get to any other computer that’s online and willing to communicate with you.
The Internet has no center and no one owns it. That’s a good thing. The Internet was designed to be redundant and fault-tolerant—meaning that if one network, connecting wire, or server stops working, everything else should keep on running. Rising from military research and work at educational institutions dating as far back as the 1960s, the Internet really took off in the 1990s, when graphical Web browsing was invented, and much of the Internet’s operating infrastructure was transitioned to be supported by private firms rather than government grants.
Figure 12.1
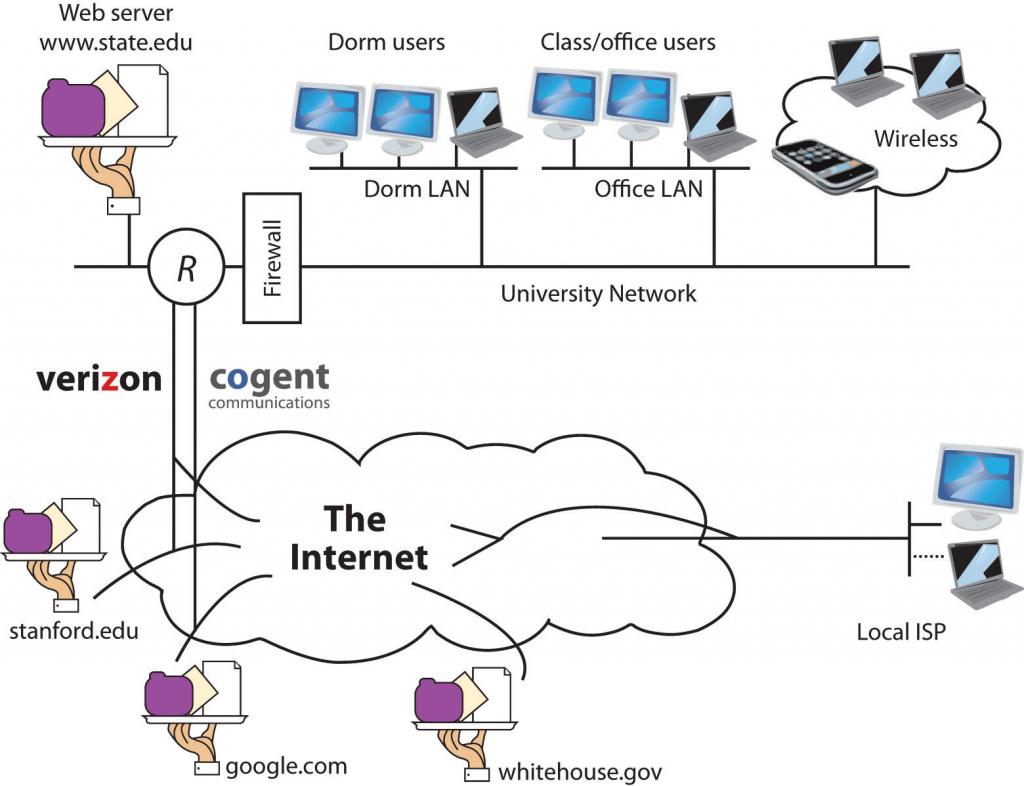
The Internet is a network of networks, and these networks are connected together. In the diagram above, the “state.edu” campus network is connected to other networks of the Internet via two ISPs: Cogent and Verizon.
Enough history—let’s see how it all works! If you want to communicate with another computer on the Internet then your computer needs to know the answer to three questions: What are you looking for? Where is it? And how do we get there? The computers and software that make up Internet infrastructure can help provide the answers. Let’s look at how it all comes together.
The URL: “What Are You Looking For?”
When you type an address into a Web browser (sometimes called a URL for uniform resource locator), you’re telling your browser what you’re looking for. Figure 12.2 “Anatomy of a Web Address” describes how to read a typical URL.
Figure 12.2 Anatomy of a Web Address

The URL displayed really says, “Use the Web (http://) to find a host server named ‘www’ in the ‘nytimes.com’ network, look in the ‘tech’ directory, and access the ‘index.html’ file.”
The http:// you see at the start of most Web addresses stands for hypertext transfer protocol. A protocol is a set of rules for communication—sort of like grammar and vocabulary in a language like English. The http protocol defines how Web browser and Web servers communicate and is designed to be independent from the computer’s hardware and operating system. It doesn’t matter if messages come from a PC, a Mac, a huge mainframe, or a pocket-sized smartphone; if a device speaks to another using a common protocol, then it will be heard and understood.
The Internet supports lots of different applications, and many of these applications use their own application transfer protocol to communicate with each other. The server that holds your e-mail uses something called SMTP, or simple mail transfer protocol, to exchange mail with other e-mail servers throughout the world. FTP, or file transfer protocol, is used for—you guessed it—file transfer. FTP is how most Web developers upload the Web pages, graphics, and other files for their Web sites. Even the Web uses different protocols. When you surf to an online bank or when you’re ready to enter your payment information at the Web site of an Internet retailer, the http at the beginning of your URL will probably change to https (the “s” is for secure). That means that communications between your browser and server will be encrypted for safe transmission. The beauty of the Internet infrastructure is that any savvy entrepreneur can create a new application that rides on top of the Internet.
Hosts and Domain Names
The next part of the URL in our diagram holds the host and domain name. Think of the domain name as the name of the network you’re trying to connect to, and think of the host as the computer you’re looking for on that network.
Many domains have lots of different hosts. For example, Yahoo!’s main Web site is served from the host named “www” (at the address http://www.yahoo.com), but Yahoo! also runs other hosts including those named “finance” (finance.yahoo.com), “sports” (sports.yahoo.com), and “games” (games.yahoo.com).
Host and Domain Names: A Bit More Complex Than That
While it’s useful to think of a host as a single computer, popular Web sites often have several computers that work together to share the load for incoming requests. Assigning several computers to a host name offers load balancing and fault tolerance, helping ensure that all visits to a popular site like http://www.google.com won’t overload a single computer, or that Google doesn’t go down if one computer fails.
It’s also possible for a single computer to have several host names. This might be the case if a firm were hosting several Web sites on a single piece of computing hardware.
Some domains are also further broken down into subdomains—many times to represent smaller networks or subgroups within a larger organization. For example, the address http://www.rhsmith.umd.edu is a University of Maryland address with a host “www” located in the subdomain “rhsmith” for the Robert H. Smith School of Business. International URLs might also include a second-level domain classification scheme. British URLs use this scheme, for example, with the BBC carrying the commercial (.co) designation—http://www.bbc.co.uk—and the University of Oxford carrying the academic (.ac) designation—http://www.ox.ac.uk. You can actually go 127 levels deep in assigning subdomains, but that wouldn’t make it easy on those who have to type in a URL that long.
Most Web sites are configured to load a default host, so you can often eliminate the host name if you want to go to the most popular host on a site (the default host is almost always named “www”). Another tip: most browsers will automatically add the “http://” for you, too.
Host and domain names are not case sensitive, so you can use a combination of upper and lower case letters and you’ll still get to your destination.
I Want My Own Domain
You can stake your domain name claim in cyberspace by going through a firm called a domain name registrar. You don’t really buy a domain name; you simply pay a registrar for the right to use that name, with the right renewable over time. While some registrars simply register domain names, others act as Web hosting services that are able to run your Web site on their Internet-connected servers for a fee.
Registrars throughout the world are accredited by ICANN (Internet Corporation for Assigning Names and Numbers), a nonprofit governance and standards-setting body. Each registrar may be granted the ability to register domain names in one or more of the Net’s generic top-level domains (gTLDs), such as “.com,” “.net,” or “.org.” There are dozens of registrars that can register “.com” domain names, the most popular gTLD.
Some generic top-level domain names, like “.com,” have no restrictions on use, while others limit registration. For example, “.edu” is restricted to U.S.-accredited, postsecondary institutions. ICANN has also announced plans to allow organizations to sponsor their own top-level domains (e.g., “.berlin,” or “.coke”).
There are also separate agencies that handle over 250 different two-character country code top-level domains, or ccTLDs (e.g., “.uk” for the United Kingdom and “.jp” for Japan). Servers or organizations generally don’t need to be housed within a country to use a country code as part of their domain names, leading to a number of creatively named Web sites. The URL-shortening site “bit.ly” uses Libya’s “.ly” top-level domain; many physicians are partial to Moldova’s code (“.md”); and the tiny Pacific island nation of Tuvulu might not have a single broadcast television station, but that doesn’t stop it from licensing its country code to firms that want a “.tv” domain name (Maney, 2004). Recent standards also allow domain names in languages that use non-Latin alphabets such as Arabic and Russian.
Domain name registration is handled on a first-come, first-served basis and all registrars share registration data to ensure that no two firms gain rights to the same name. Start-ups often sport wacky names, partly because so many domains with common words and phrases are already registered to others. While some domain names are held by legitimate businesses, others are registered by investors hoping to resell a name’s rights.
Trade in domain names can be lucrative. For example, the “Insure.com” domain was sold to QuinStreet for $16 million in fall 2009 (Bosker, 2010). But knowingly registering a domain name to profit from someone else’s firm name or trademark is known as cybersquatting and that’s illegal. The United States has passed the Anticybersquatting Consumer Protection Act (ACPA), and ICANN has the Domain Name Dispute Resolution Policy that can reach across boarders. Try to extort money by holding a domain name that’s identical to (or in some cases, even similar to) a well-known trademark holder and you could be stripped of your domain name and even fined.
Courts and dispute resolution authorities will sometimes allow a domain that uses the trademark of another organization if it is perceived to have legitimate, nonexploitive reasons for doing so. For example, the now defunct site Verizonreallysucks.com was registered as a protest against the networking giant and was considered fair use since owners didn’t try to extort money from the telecom giant (Streitfeld, 2000). However, the courts allowed the owner of the PETA trademark (the organization People for the Ethical Treatment of Animals) to claim the domain name peta.org from original registrant, who had been using that domain to host a site called “People Eating Tasty Animals” (McCullagh, 2001).
Trying to predict how authorities will rule can be difficult. The musician Sting’s name was thought to be too generic to deserve the rights to Sting.com, but Madonna was able to take back her domain name (for the record, Sting now owns Sting.com) (Knorad & Hansen, 2000). Apple executive Jonathan Ive was denied the right to reclaim domain names incorporating his own name, but that had been registered by another party and without his consent. The publicity-shy design guru wasn’t considered enough of a public figure to warrant protection (Morson, 2009). And sometimes disputing parties can come to an agreement outside of court or ICANN’s dispute resolution mechanisms. When Canadian teenager Michael Rowe registered a site for his part-time Web design business, a firm south of the border took notice of his domain name—Mikerowesoft.com. The two parties eventually settled in a deal that swapped the domain for an Xbox and a trip to the Microsoft Research Tech Fest (Kotadia, 2004).
Path Name and File Name
Look to the right of the top-level domain and you might see a slash followed by either a path name, a file name, or both. If a Web address has a path and file name, the path maps to a folder location where the file is stored on the server; the file is the name of the file you’re looking for.
Most Web pages end in “.html,” indicating they are in hypertext markup language. While http helps browsers and servers communicate, html is the language used to create and format (render) Web pages. A file, however, doesn’t need to be .html; Web servers can deliver just about any type of file: Acrobat documents (.pdf), PowerPoint documents (.ppt or .pptx), Word docs (.doc or .docx), JPEG graphic images (.jpg), and—as we’ll see in Chapter 13 “Information Security: Barbarians at the Gateway (and Just About Everywhere Else)”—even malware programs that attack your PC. At some Web addresses, the file displays content for every visitor, and at others (like amazon.com), a file will contain programs that run on the Web server to generate custom content just for you.
You don’t always type a path or file name as part of a Web address, but there’s always a file lurking behind the scenes. A Web address without a file name will load content from a default page. For example, when you visit “google.com,” Google automatically pulls up a page called “index.html,” a file that contains the Web page that displays the Google logo, the text entry field, the “Google Search” button, and so on. You might not see it, but it’s there.
Butterfingers, beware! Path and file names are case sensitive—amazon.com/books is considered to be different from amazon.com/BOOKS. Mistype your capital letters after the domain name and you might get a 404 error (the very unfriendly Web server error code that means the document was not found).
IP Addresses and the Domain Name System: “Where Is It? And How Do We Get There?”
The IP Address
If you want to communicate, then you need to have a way for people to find and reach you. Houses and businesses have street addresses, and telephones have phone numbers. Every device connected to the Internet has an identifying address, too—it’s called an IP (Internet protocol) address.
A device gets its IP address from whichever organization is currently connecting it to the Internet. Connect using a laptop at your university and your school will assign the laptop’s IP address. Connect at a hotel, and the hotel’s Internet service provider lends your laptop an IP address. Laptops and other end-user machines might get a different IP address each time they connect, but the IP addresses of servers rarely change. It’s OK if you use different IP addresses during different online sessions because services like e-mail and Facebook identify you by your username and password. The IP address simply tells the computers that you’re communicating with where they can find you right now. IP addresses can also be used to identify a user’s physical location, to tailor search results, and to customize advertising. See Chapter 14 “Google: Search, Online Advertising, and Beyond” to learn more.
IP addresses are usually displayed as a string of four numbers between 0 and 255, separated by three periods. Want to know which IP address your smartphone or computer is using? Visit a Web site like ip-adress.com (one “d”), whatismyipaddress.com, or ipchicken.com.
The Internet Is Almost Full
If you do the math, four combinations of 0 to 255 gives you a little over four billion possible IP addresses. Four billion sounds like a lot, but the number of devices connecting to the Internet is exploding! Internet access is now baked into smartphones, tablets, televisions, DVD players, video game consoles, utility meters, thermostats, appliances, picture frames, and more. Another problem is a big chunk of existing addresses weren’t allocated efficiently, and these can’t be easily reclaimed from the corporations, universities, and other organizations that initially received them. All of this means that we’re running out of IP addresses. Experts differ on when ICANN will have no more numbers to dole out, but most believe that time will come by 2012, if not sooner (Ward, 2010).
There are some schemes to help delay the impact of this IP address drought. For example, a technique known as NAT (network address translation) uses a gateway that allows multiple devices to share a single IP address. But NAT slows down Internet access and is complex, cumbersome, and expensive to administer (Shankland, 2009).
The only long-term solution is to shift to a new IP scheme. Fortunately, one was developed more than a decade ago. IPv6 increases the possible address space from the 232 (4,294,967,296) addresses used in the current system (called IPv4) to a new theoretical limit of 2128 addresses, which is a really big number—bigger than 34 with 37 zeros after it.
But not all the news is good. Unfortunately, IPv6 isn’t backward compatible with IPv4, and the transition to the new standard has been painfully slow. This gives us the equivalent of many islands of IPv6 in a sea of IPv4, with translation between the two schemes happening when these networks come together. While most modern hardware and operating systems providers now support IPv6, converting a network to IPv6 currently involves a lot of cost with little short-term benefit (Shankland, 2009). Upgrading may take years and is likely to result in rollout problems. David Conrad, a general manager at Internet Assigned Numbers Authority (IANA), the agency that grants permission to use IP addresses, has said, “I suspect we are actually beyond a reasonable time frame where there won’t be some disruption. It’s just a question of how much” (Arnoldy, 2007).
Some organizations have stepped up to try to hasten transition. Google has made most of its services IPv6 accessible, the U.S. government has mandated IPv6 support for most agencies, China has spurred conversion within its borders, and Comcast and Verizon have major IPv6 rollouts under way. While the transition will be slow, when wide scale deployment does arrive, IPv6 will offer other benefits, including potentially improving the speed, reliability, and security of the Internet.
The DNS: The Internet’s Phonebook
You can actually type an IP address of a Web site into a Web browser and that page will show up. But that doesn’t help users much because four sets of numbers are really hard to remember.
This is where the domain name service (DNS) comes in. The domain name service is a distributed database that looks up the host and domain names that you enter and returns the actual IP address for the computer that you want to communicate with. It’s like a big, hierarchical set of phone books capable of finding Web servers, e-mail servers, and more. These “phone books” are called nameservers—and when they work together to create the DNS, they can get you anywhere you need to go online.
Figure 12.3
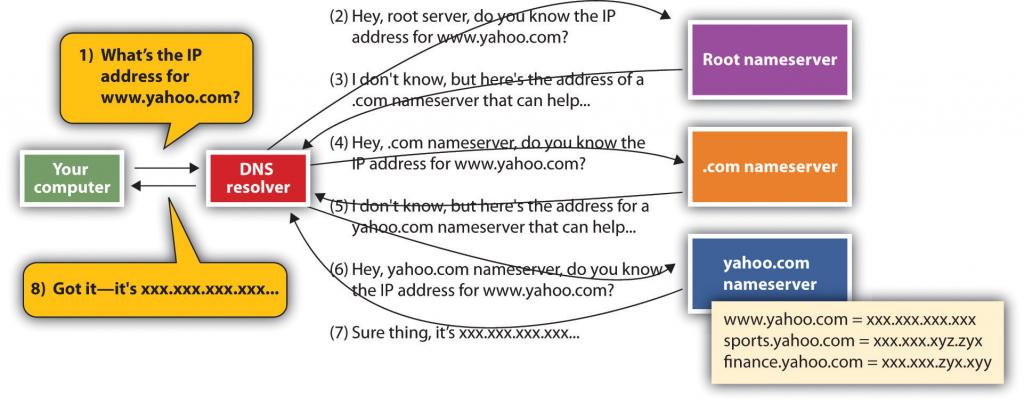
When your computer needs to find the IP address for a host or domain name, it sends a message to a DNS resolver, which looks up the IP address starting at the root nameserver. Once the lookup has taken place, that IP address can be saved in a holding space called a cache, to speed future lookups.
To get a sense of how the DNS works, let’s imagine that you type www.yahoo.com into a Web browser. Your computer doesn’t know where to find that address, but when your computer connected to the network, it learned where to find a service on the network called a DNS resolver. The DNS resolver can look up host/domain name combinations to find the matching IP address using the “phone book” that is the DNS. The resolver doesn’t know everything, but it does know where to start a lookup that will eventually give you the address you’re looking for. If this is the first time anyone on that network has tried to find “www.yahoo.com,” the resolver will contact one of thirteen identical root nameservers. The root acts as a lookup starting place. It doesn’t have one big list, but it can point you to a nameserver for the next level, which would be one of the “.com” nameservers in our example. The “.com” nameserver can then find one of the yahoo.com nameservers. The yahoo.com nameserver can respond to the resolver with the IP address for www.yahoo.com, and the resolver passes that information back to your computer. Once your computer knows Yahoo!’s IP address, it’s then ready to communicate directly with www.yahoo.com. The yahoo.com nameserver includes IP addresses for all Yahoo!’s public sites: www.yahoo.com, games.yahoo.com, sports.yahoo.com, finance.yahoo.com, and so on.
The system also remembers what it’s done so the next time you need the IP address of a host you’ve already looked up, your computer can pull this out of a storage space called a cache, avoiding all those nameserver visits. Caches are periodically cleared and refreshed to ensure that data referenced via the DNS stays accurate.
Distributing IP address lookups this way makes sense. It avoids having one huge, hard-to-maintain, and ever-changing list. Firms add and remove hosts on their own networks just by updating entries in their nameserver. And it allows host IP addresses to change easily, too. Moving your Web server off-site to a hosting provider? Just update your nameserver with the new IP address at the hosting provider, and the world will invisibly find that new IP address on the new network by using the same old, familiar host/domain name combination. The DNS is also fault-tolerant—meaning that if one nameserver goes down, the rest of the service can function. There are exact copies at each level, and the system is smart enough to move on to another nameserver if its first choice isn’t responding.
But What If the DNS Gets Hacked?
A hacked DNS would be a disaster! Think about it. If bad guys could change which Web sites load when you type in a host and domain name, they could redirect you to impostor Web sites that look like a bank or e-commerce retailer but are really set up to harvest passwords and credit card data.
This exact scenario played out when the DNS of NET Virtua, a Brazilian Internet service provider, was hacked via a technique called DNS cache poisoning. Cache poisoning exploits a hole in DNS software, redirecting users to sites they didn’t request. The Brazilian DNS hack redirected NET Virtua users wishing to visit the Brazilian bank Bradesco to fraudulent Web sites that attempted to steal passwords and install malware. The hack impacted about 1 percent of the bank’s customers before the attack was discovered (Godin, 2009).
The exploit showed the importance of paying attention to security updates. A few months earlier, a group that Wired magazine referred to as “A Secret Geek A-Team” (Davis, 2008) had developed a software update that would have prevented the DNS poisoning exploit used against NET Virtua, but administrators at the Brazilian Internet service provider failed to update their software so the hackers got in. An additional upgrade to a DNS system, known as DNSSEC (domain name service security extensions), promises to further limit the likelihood of cache poisoning, but it may take years for the new standards to be rolled out everywhere (Hutchinson, 2010).
Key Takeaways
- The Internet is a network of networks. Internet service providers connect with one another to share traffic, enabling any Internet-connected device to communicate with any other.
- URLs may list the application protocol, host name, domain name, path name, and file name, in that order. Path and file names are case sensitive.
- A domain name represents an organization. Hosts are public services offered by that organization. Hosts are often thought of as a single computer, although many computers can operate under a single host name and many hosts can also be run off a single computer.
- You don’t buy a domain name but can register it, paying for a renewable right to use that domain name. Domains need to be registered within a generic top-level domain such as “.com” or “.org” or within a two-character country code top-level domain such as “.uk,” “.ly,” or “.md.”
- Registering a domain that uses someone else’s trademark in an attempt to extract financial gain is considered cybersquatting. The United States and other nations have anticybersquatting laws, and ICANN has a dispute resolution system that can overturn domain name claims if a registrant is considered to be cybersquatting.
- Every device connected to the Internet has an IP address. These addresses are assigned by the organization that connects the user to the Internet. An IP address may be assigned temporarily, for use only during that online session.
- We’re running out of IP addresses. The current scheme (IPv4) is being replaced by IPv6, a scheme that will give us many more addresses and additional feature benefits but is not backward compatible with the IPv4 standard. Transitioning to IPv6 will be costly and take time.
- The domain name system is a distributed, fault-tolerant system that uses nameservers to map host/domain name combinations to IP addresses.
Questions and Exercises
- Find the Web page for your school’s information systems department. What is the URL that gets you to this page? Label the host name, domain name, path, and file for this URL. Are there additional subdomains? If so, indicate them, as well.
- Go to a registrar and see if someone has registered your first or last name as a domain name. If so, what’s hosted at that domain? If not, would you consider registering your name as a domain name? Why or why not?
- Investigate cases of domain name disputes. Examine a case that you find especially interesting. Who were the parties involved? How was the issue resolved? Do you agree with the decision?
- Describe how the DNS is fault-tolerant and promotes load balancing. Give examples of other types of information systems that might need to be fault-tolerant and offer load balancing. Why?
- Research DNS poisoning online. List a case, other than the one mentioned in this chapter, where DNS poisoning took place. Which network was poisoned, who were the victims, and how did hackers exploit the poisoned system? Could this exploit have been stopped? How? Whose responsibility is it to stop these kinds of attacks?
- Why is the switch from IPv4 to IPv6 so difficult? What key principles, discussed in prior chapters, are slowing migration to the new standard?
References
Arnoldy, B., “IP Address Shortage to Limit Internet Access,” USA Today, August 3, 2007.
Bosker, B., “The 11 Most Expensive Domain Names Ever,” The Huffington Post, March 10, 2010.
Davis, J., “Secret Geek A-Team Hacks Back, Defends Worldwide Web,” Wired, Nov. 24, 2008.
Godin, D., “Cache-Poisoning Attack Snares Top Brazilian Bank,” The Register, April 22, 2009.
Hutchinson, J., “ICANN, Verisign Place Last Puzzle Pieces in DNSSEC Saga,” NetworkWorld, May 2, 2010.
Konrad R. and E. Hansen, “Madonna.com Embroiled in Domain Ownership Spat,” CNET, August 21, 2000.
Kotadia, M., “MikeRoweSoft Settles for an Xbox,” CNET, January 26, 2004.
Maney, K., “Tuvalu’s Sinking, But Its Domain Is on Solid Ground,” USA Today, April 27, 2004.
McCullagh, D., “Ethical Treatment of PETA Domain,” Wired, August 25, 2001.
Morson, D., “Apple VP Ive Loses Domain Name Bid,” MacWorld, May 12, 2009.
Shankland, S., “Google Tries to Break IPv6 Logjam by Own Example,” CNET, March 27, 2009.
Streitfeld, D., “Web Site Feuding Enters Constitutional Domain,” The Washington Post, September 11, 2000.
Ward, M., “Internet Approaches Addressing Limit,” BBC News, May 11, 2010.
