
11.2 – DNA Replication
Learning Objectives
- Explain the meaning of semiconservative DNA replication
- Explain why DNA replication is bidirectional and includes both a leading and lagging strand
- Explain why Okazaki fragments are formed
- Describe the process of DNA replication and the functions of the enzymes involved
- Identify the differences between DNA replication in bacteria and eukaryotes
- Explain the process of rolling circle replication
The elucidation of the structure of the double helix by James Watson and Francis Crick in 1953 provided a hint as to how DNA is copied during the process of replication. Separating the strands of the double helix would provide two templates for the synthesis of new complementary strands, but exactly how new DNA molecules were constructed was still unclear. In one model, semiconservative replication, the two strands of the double helix separate during DNA replication, and each strand serves as a template from which the new complementary strand is copied; after replication, each double-stranded DNA includes one parental or “old” strand and one “new” strand. There were two competing models also suggested: conservative and dispersive, which are shown in Figure 11.4.
Microbial Informatics and Experimentation 3 no. 1 (2013):2.
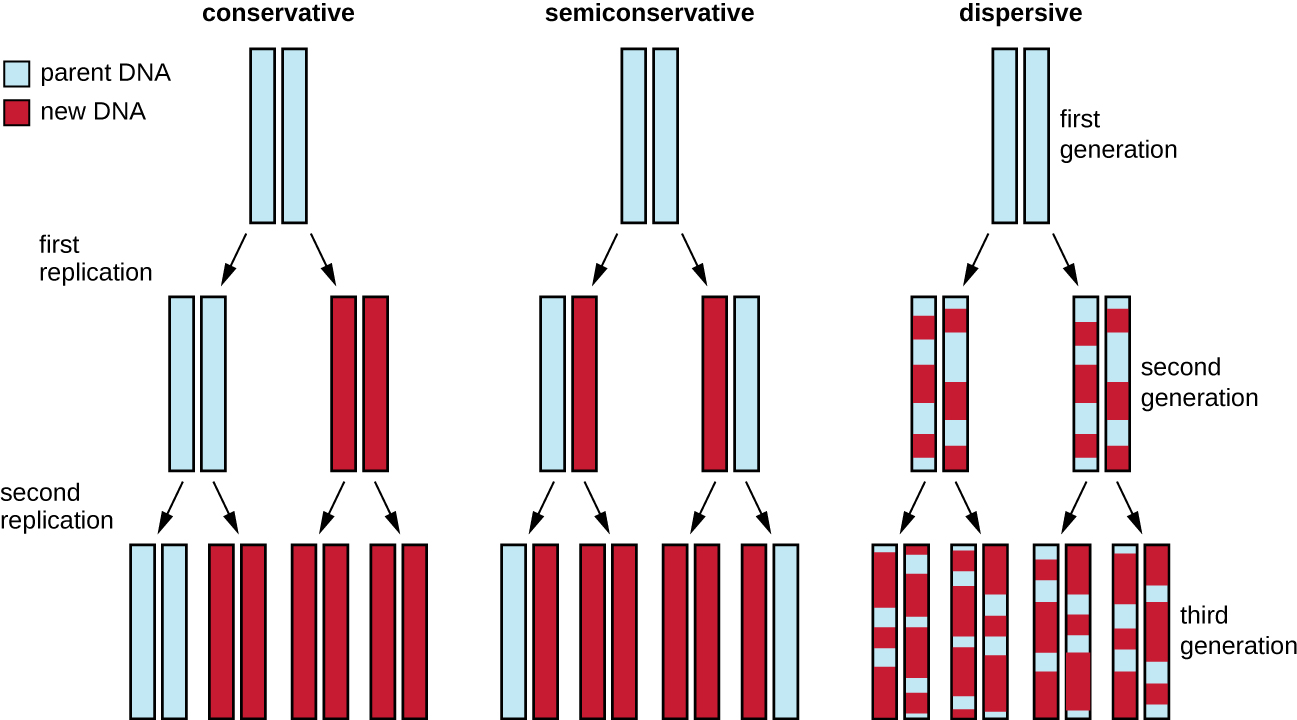
Diagram showing 3 models of DNA replication. In the conservative model the original double helix produces two double helices; one of which has two of the parent strands and one of which has two of the new strands. Another round produces 4 helices; one of which has two of the parent strands and three of which have all new strands. In semiconservative replication the first round leads to two double helices each with one old strand and one new strand. The next round leads to four double helices; two of these have an old and a new strand and two have all new strands. In dispersive replication each new round of replication results in strands with random bits from the parent strand and random bits of new strands.
Matthew Meselson (1930–) and Franklin Stahl (1929–) devised an experiment in 1958 to test which of these models correctly represents DNA replication (Figure 11.5). They grew E. coli for several generations in a medium containing a “heavy” isotope of nitrogen (15N) that was incorporated into nitrogenous bases and, eventually, into the DNA. This labeled the parental DNA. The E. coli culture was then shifted into a medium containing 14N and allowed to grow for one generation. The cells were harvested and the DNA was isolated. The DNA was separated by ultracentrifugation, during which the DNA formed bands according to its density. DNA grown in 15N would be expected to form a band at a higher density position than that grown in 14N. Meselson and Stahl noted that after one generation of growth in 14N, the single band observed was intermediate in position in between DNA of cells grown exclusively in 15N or 14N. This suggested either a semiconservative or dispersive mode of replication. Some cells were allowed to grow for one more generation in 14N and spun again. The DNA harvested from cells grown for two generations in 14N formed two bands: one DNA band was at the intermediate position between 15N and 14N, and the other corresponded to the band of 14N DNA. These results could only be explained if DNA replicates in a semiconservative manner. Therefore, the other two models were ruled out. As a result of this experiment, we now know that during DNA replication, each of the two strands that make up the double helix serves as a template from which new strands are copied. The new strand will be complementary to the parental or “old” strand. The resulting DNA molecules have the same sequence and are divided equally into the two daughter cells.
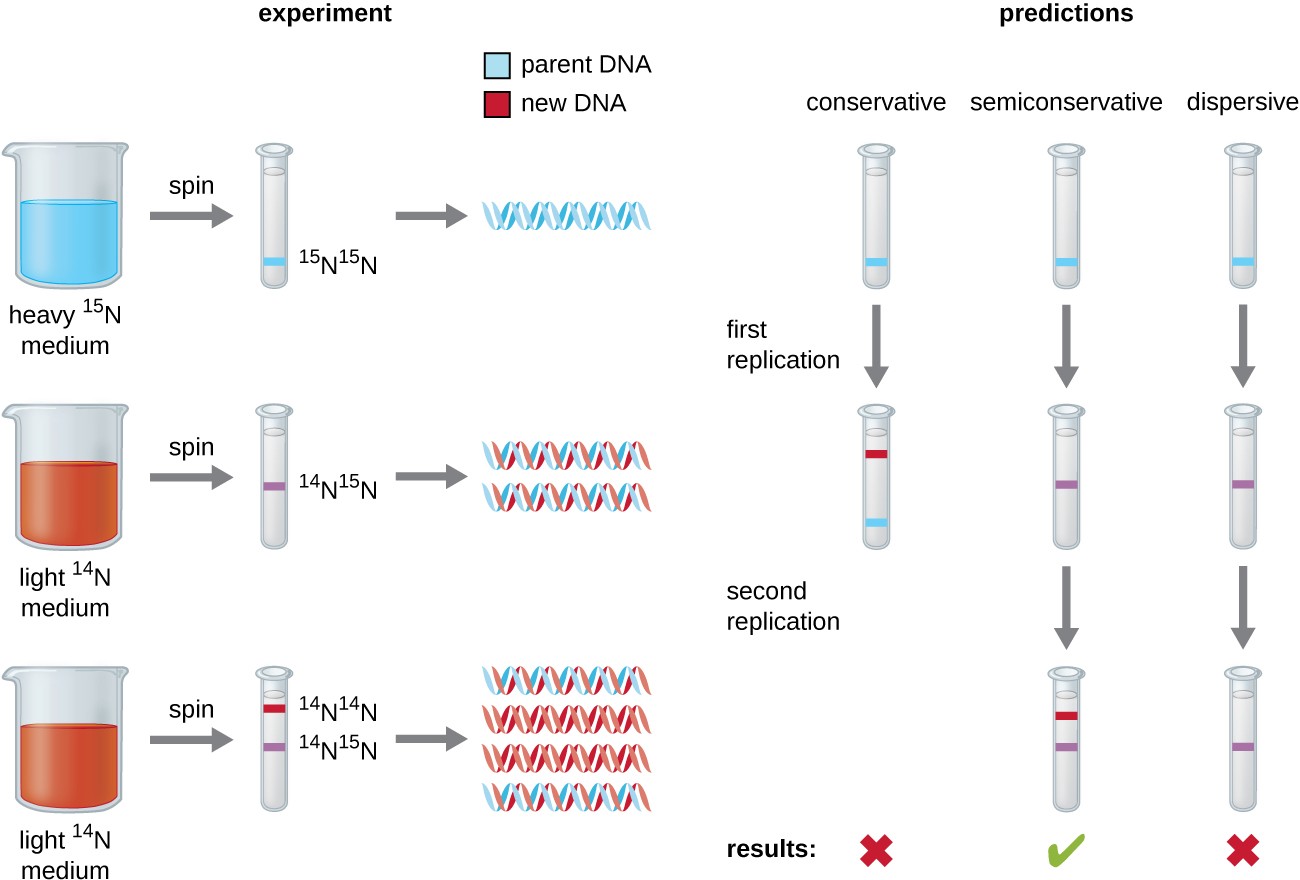
Diagram showing 3 models of DNA replication. In the conservative model the original double helix produces two double helices; one of which has two of the parent strands and one of which has two of the new strands. Another round produces 4 helices; one of which has two of the parent strands and three of which have all new strands. In semiconservative replication the first round leads to two double helices each with one old strand and one new strand. The next round leads to four double helices; two of these have an old and a new strand and two have all new strands. In dispersive replication each new round of replication results in strands with random bits from the parent strand and random bits of new strandsA diagram explaining the Meselson Stahl experiment. In the first part of the experiment DNA is replicated in the presence of heavy 15N medium. This produces all heavy DNA strands. Next they moved the cells to light 14N medium. If DNA was replicated conservatively, one would expect to see one heavy band and one light band. However, they saw only a medium size band. This is consistent with semiconservative and dispersive replication. Finally, they allowed the bacteria to undergo another round of replication in the light medium. If DNA was replicated dispersively, one would expect only a medium size band. However, they saw a medium band and a light band. The only mechanism that explains these results is semi-conservative replication.
Check Your Understanding
- What would have been the conclusion of Meselson and Stahl’s experiment if, after the first generation, they had found two bands of DNA?
DNA Replication in Bacteria
DNA replication has been well studied in bacteria primarily because of the small size of the genome and the mutants that are available. E. coli has 4.6 million base pairs (Mbp) in a single circular chromosome and all of it is replicated in approximately 42 minutes, starting from a single origin of replication and proceeding around the circle bidirectionally (i.e., in both directions). This means that approximately 1000 nucleotides are added per second. The process is quite rapid and occurs with few errors.
DNA replication uses a large number of proteins and enzymes (Table 11.1). One of the key players is the enzyme DNA polymerase, also known as DNA pol. In bacteria, three main types of DNA polymerases are known: DNA pol I, DNA pol II, and DNA pol III. It is now known that DNA pol III is the enzyme required for DNA synthesis; DNA pol I and DNA pol II are primarily required for repair. DNA pol III adds deoxyribonucleotides each complementary to a nucleotide on the template strand, one by one to the 3’-OH group of the growing DNA chain. The addition of these nucleotides requires energy. This energy is present in the bonds of three phosphate groups attached to each nucleotide (a triphosphate nucleotide), similar to how energy is stored in the phosphate bonds of adenosine triphosphate (ATP) (Figure 11.6). When the bond between the phosphates is broken and diphosphate is released, the energy released allows for the formation of a covalent phosphodiester bond by dehydration synthesis between the incoming nucleotide and the free 3’-OH group on the growing DNA strand.
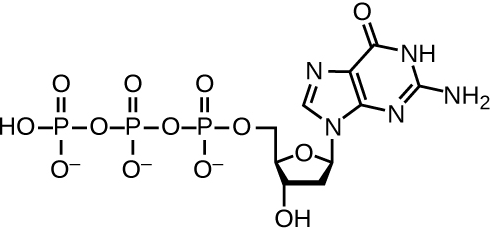
Diagram of dGTP. In the center is deoxyribose which is a pentagon shaped sugar. The top point has an oxygen. Then, moving around the shape are carbons 1, 2, 3, and 4; carbon 5 is attached to carbon 4 but not in the ring. Attached to carbon 1 is a structure made of 2 carbon and nitrogen rings bound along their ends; this is guanine. Carbon 2 has only Hs attached to it. Carbon 3 has an H and an OH. Carbon 4 has an N and Carbon 5. Carbon 5 is attached to 3 phosphate groups in a row (labeled triphosphate). Each phosphate group is made of phosphorus attached to 4 oxygen atoms.
Initiation
The initiation of replication occurs at specific nucleotide sequence called the origin of replication, where various proteins bind to begin the replication process. E. coli has a single origin of replication (as do most prokaryotes), called oriC, on its one chromosome. The origin of replication is approximately 245 base pairs long and is rich in adenine- thymine (AT) sequences.
Some of the proteins that bind to the origin of replication are important in making single-stranded regions of DNA accessible for replication. Chromosomal DNA is typically wrapped around histones (in eukaryotes and archaea) or histone-like proteins (in bacteria), and is supercoiled, or extensively wrapped and twisted on itself. This packaging makes the information in the DNA molecule inaccessible. However, enzymes called topoisomerases change the shape and supercoiling of the chromosome. For bacterial DNA replication to begin, the supercoiled chromosome is relaxed by topoisomerase II, also called DNA gyrase. An enzyme called helicase then separates the DNA strands by breaking the hydrogen bonds between the nitrogenous base pairs. Recall that AT sequences have fewer hydrogen bonds and, hence, have weaker interactions than guanine-cytosine (GC) sequences. These enzymes require ATP hydrolysis. As the DNA opens up, Y-shaped structures called replication forks are formed. Two replication forks are formed at the origin of replication, allowing for bidirectional replication and formation of a structure that looks like a bubble when viewed with a transmission electron microscope; as a result, this structure is called a replication bubble. The DNA near each replication fork is coated with single-stranded binding proteins to prevent the single- stranded DNA from rewinding into a double helix.
Once single-stranded DNA is accessible at the origin of replication, DNA replication can begin. However, DNA pol III is able to add nucleotides only in the 5’ to 3’ direction (a new DNA strand can be only extended in this direction). This is because DNA polymerase requires a free 3’-OH group to which it can add nucleotides by forming a covalent phosphodiester bond between the 3’-OH end and the 5’ phosphate of the next nucleotide. This also means that it cannot add nucleotides if a free 3’-OH group is not available, which is the case for a single strand of DNA. The problem is solved with the help of an RNA sequence that provides the free 3’-OH end. Because this sequence allows the start of DNA synthesis, it is appropriately called the primer. The primer is five to 10 nucleotides long and complementary to the parental or template DNA. It is synthesized by RNA primase, which is an RNA polymerase. Unlike DNA polymerases, RNA polymerases do not need a free 3’-OH group to synthesize an RNA molecule. Now that the primer provides the free 3’-OH group, DNA polymerase III can now extend this RNA primer, adding DNA nucleotides one by one that are complementary to the template strand (Figure 11.4).
Elongation
During elongation in DNA replication, the addition of nucleotides occurs at its maximal rate of about 1000 nucleotides per second. DNA polymerase III can only extend in the 5’ to 3’ direction, which poses a problem at
the replication fork. The DNA double helix is antiparallel; that is, one strand is oriented in the 5’ to 3’ direction and the other is oriented in the 3’ to 5’ direction (see Structure and Function of DNA). During replication, one strand, which is complementary to the 3’ to 5’ parental DNA strand, is synthesized continuously toward the replication fork because polymerase can add nucleotides in this direction. This continuously synthesized strand is known as the leading strand. The other strand, complementary to the 5’ to 3’ parental DNA, grows away from the replication fork, so the polymerase must move back toward the replication fork to begin adding bases to a new primer, again in the direction away from the replication fork. It does so until it bumps into the previously synthesized strand and then it moves back again (Figure 11.7). These steps produce small DNA sequence fragments known as Okazaki fragments, each separated by RNA primer. Okazaki fragments are named after the Japanese research team and married couple Reiji and Tsuneko Okazaki, who first discovered them in 1966. The strand with the Okazaki fragments is known as the lagging strand, and its synthesis is said to be discontinuous.
The leading strand can be extended from one primer alone, whereas the lagging strand needs a new primer for each of the short Okazaki fragments. The overall direction of the lagging strand will be 3’ to 5’, and that of the leading strand 5’ to 3’. A protein called the sliding clamp holds the DNA polymerase in place as it continues to add nucleotides. The sliding clamp is a ring-shaped protein that binds to the DNA and holds the polymerase in place. Beyond its role in initiation, topoisomerase also prevents the overwinding of the DNA double helix ahead of the replication fork as the DNA is opening up; it does so by causing temporary nicks in the DNA helix and then resealing it. As synthesis proceeds, the RNA primers are replaced by DNA. The primers are removed by the exonuclease activity of DNA polymerase I, and the gaps are filled in. The nicks that remain between the newly synthesized DNA (that replaced the RNA primer) and the previously synthesized DNA are sealed by the enzyme DNA ligase that catalyzes the formation of covalent phosphodiester linkage between the 3’-OH end of one DNA fragment and the 5’ phosphate end of the other fragment, stabilizing the sugar-phosphate backbone of the DNA molecule.
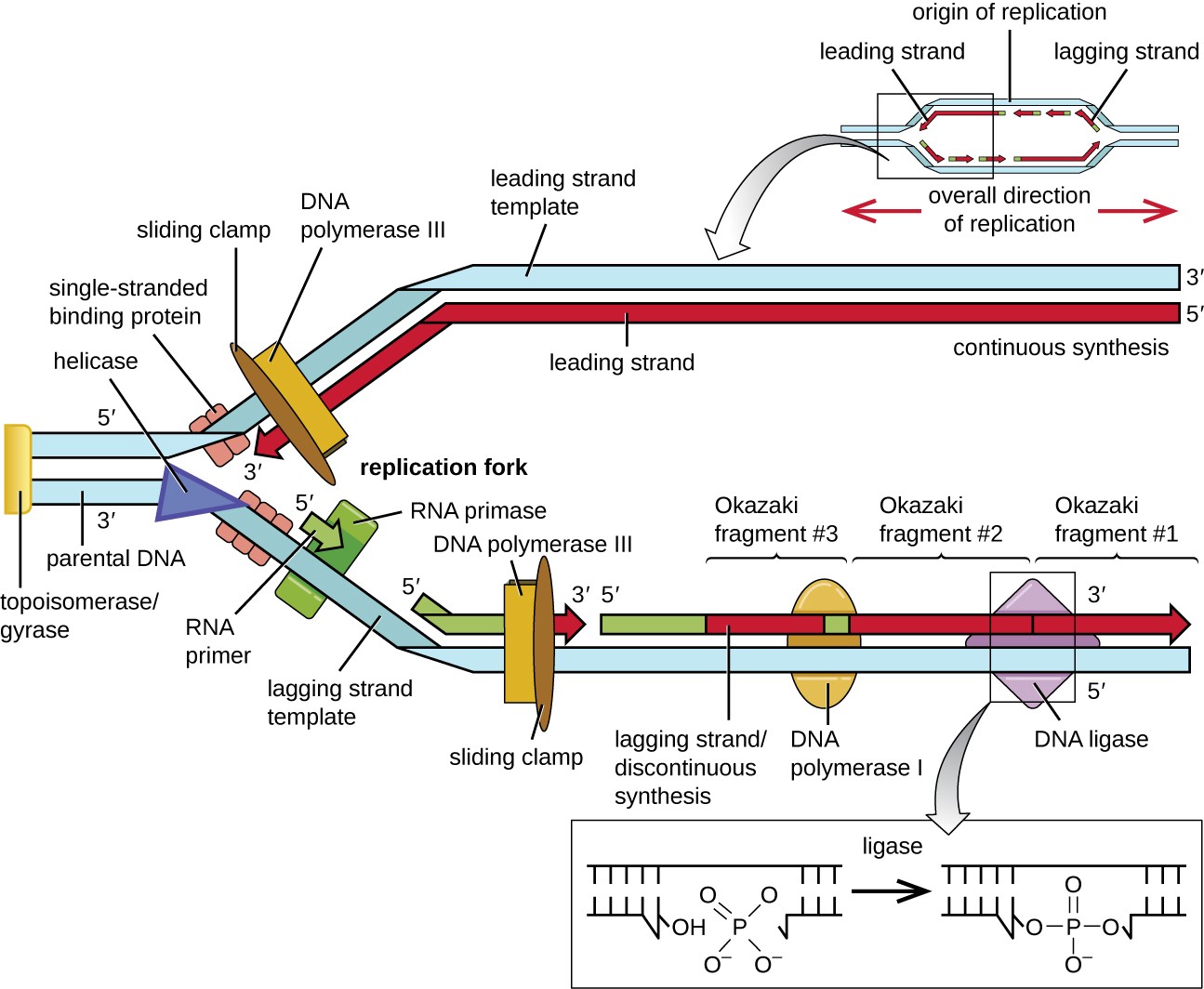
Diagram of DNA replication. A small inset at the top shows a double strand of DNA separated in the center forming a bubble; the DNA is double stranded on either side of the bubble. The origin of replication is in the midway point of the bubble. On the top strand a solid arrow points to the left from the origin; this is the leading strand. On the right of the origin of replication are short arrows pointing to the left; this is the lagging strand. On the bottom strand a solid arrow pointing to the right from the origin is labeled leading strand and short arrows pointing to the right on the other side of the origin are labeled lagging strands. A larger image shows just the left half of the bubble. The double stranded DNA is no the far left and is labeled 5’ for the top strand and 3’ for the bottom strand. An enzyme to the very far left I is labeled topoisomerase/gyrase. At the point where the double stranded regions splits is a triangle shape labeled helicase. Next to that are smaller shapes labeled single-stranded binding proteins. The top strand shows continuous synthesis of the leading strand; this is shown as a solid arrow under the top strand. The arrow has a 5’ at the right end and a 3’ at the left end. The template strand at the top has a 3’ at the right and a 5’ at the left. At the end of the arrow (near where the DNA is newly being separated by the helicase) is DNA polymerase 3 and a sliding clamp that span both strands. The bottom strand of DNA has more components. Just after the single stranded binding proteins is RNA primase which attaches RNA primer (shown as a green arrow). Further down the lagging strand template is an existing RNA primer with DNA polymerase III and a sliding clamp spanning primer and the template strand. The polymerase is building a new strand of DNA from the left side (5’) to the right side (3’). Further to the right is a long piece made of RNA primer, then new DNA, then RNA primer, then new DNA all connected. Each of the DNA/RNA combinations are okazaki fragments made in the discontinuous synthesis of the lagging strand. DNA polymerase I is attached to the RNA primer in the center and is replacing it with DNA nucleotides. DNA ligase then binds the individual strands of new DNA together. This is shown in a close-up as two double helices that have all the correct letters in place, but one is missing a connection between two of the nucleotides (this is called a single-stranded gap). DNA ligase forms this last bond and the gap is sealed.
Termination
Once the complete chromosome has been replicated, termination of DNA replication must occur. Although much is known about initiation of replication, less is known about the termination process. Following replication, the resulting complete circular genomes of prokaryotes are concatenated, meaning that the circular DNA chromosomes are interlocked and must be separated from each other. This is accomplished through the activity of bacterial topoisomerase IV, which introduces double-stranded breaks into DNA molecules, allowing them to separate from each other; the enzyme then reseals the circular chromosomes. The resolution of concatemers is an issue unique to prokaryotic DNA replication because of their circular chromosomes. Because both bacterial DNA gyrase and topoisomerase IV are distinct from their eukaryotic counterparts, these enzymes serve as targets for a class of antimicrobial drugs called quinolones.
The Molecular Machinery Involved in Bacterial DNA Replication
| Enzyme or Factor | Function |
|---|---|
| DNA pol I | Exonuclease activity removes RNA primer and replaces it with newly synthesized DNA |
| DNA pol III | Main enzyme that adds nucleotides in the 5’ to 3’ direction |
| Helicase | Opens the DNA helix by breaking hydrogen bonds between the nitrogenous bases |
| Ligase | Seals the gaps between the Okazaki fragments on the lagging strand to create one continuous DNA strand |
| Primase | Synthesizes RNA primers needed to start replication |
| Single- stranded binding proteins | Bind to single-stranded DNA to prevent hydrogen bonding between DNA strands, reforming double-stranded DNA |
| Sliding clamp | Helps hold DNA pol III in place when nucleotides are being added |
| Topoisomerase II (DNA gyrase) | Relaxes supercoiled chromosome to make DNA more accessible for the initiation of replication; helps relieve the stress on DNA when unwinding, by causing breaks and then resealing the DNA |
| Topoisomerase IV | Introduces single-stranded break into concatenated chromosomes to release them from each other, and then reseals the DNA |
Check Your Understanding
- Which enzyme breaks the hydrogen bonds holding the two strands of DNA together so that replication can occur?
- Is it the lagging strand or the leading strand that is synthesized in the direction toward the opening of the replication fork?
- Which enzyme is responsible for removing the RNA primers in newly replicated bacterial DNA?
DNA Replication in Eukaryotes
Eukaryotic genomes are much more complex and larger than prokaryotic genomes and are typically composed of multiple linear chromosomes (Table 11.2). The human genome, for example, has 3 billion base pairs per haploid set of chromosomes, and 6 billion base pairs are inserted during replication. There are multiple origins of replication on each eukaryotic chromosome (Figure 11.8); the human genome has 30,000 to 50,000 origins of replication. The rate of replication is approximately 100 nucleotides per second—10 times slower than prokaryotic replication.
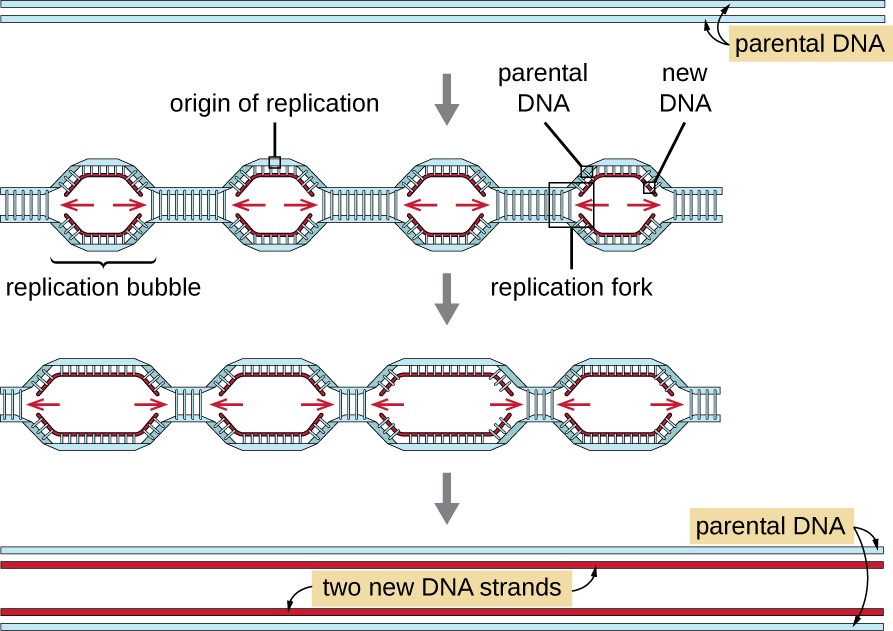
A diagram showing two strands of parental DNA. Then an arrow showing multiple replication bubbles with an origin of replication in each. Arrows point to the left and right from each origin of replication. New strands of DNA are shown being formed. One of the bubbles has the left half of the bubble in a box labeled replication fork. The next image shows the replication bubbles getting longer. The final image shows two new DNA strands, each with one old strand and one new strand.
The essential steps of replication in eukaryotes are the same as in prokaryotes. Before replication can start, the DNA has to be made available as a template. Eukaryotic DNA is highly supercoiled and packaged, which is facilitated by many proteins, including histones (see Structure and Function of Cellular Genomes). At the origin of replication, a prereplication complex composed of several proteins, including helicase, forms and recruits other enzymes involved in the initiation of replication, including topoisomerase to relax supercoiling, single-stranded binding protein, RNA primase, and DNA polymerase. Following initiation of replication, in a process similar to that found in prokaryotes, elongation is facilitated by eukaryotic DNA polymerases. The leading strand is continuously synthesized by the eukaryotic polymerase enzyme pol δ, while the lagging strand is synthesized by pol ε. A sliding clamp protein holds the DNA polymerase in place so that it does not fall off the DNA. The enzyme ribonuclease H (RNase H), instead of a DNA polymerase as in bacteria, removes the RNA primer, which is then replaced with DNA nucleotides. The gaps that remain are sealed by DNA ligase.
Because eukaryotic chromosomes are linear, one might expect that their replication would be more straightforward. As in prokaryotes, the eukaryotic DNA polymerase can add nucleotides only in the 5’ to 3’ direction. In the leading strand, synthesis continues until it reaches either the end of the chromosome or another replication fork progressing in the opposite direction. On the lagging strand, DNA is synthesized in short stretches, each of which is initiated by a separate primer. When the replication fork reaches the end of the linear chromosome, there is no place to make a primer for the DNA fragment to be copied at the end of the chromosome. These ends thus remain unpaired and, over time, they may get progressively shorter as cells continue to divide.
The ends of the linear chromosomes are known as telomeres and consist of noncoding repetitive sequences. The telomeres protect coding sequences from being lost as cells continue to divide. In humans, a six base-pair sequence, TTAGGG, is repeated 100 to 1000 times to form the telomere. The discovery of the enzyme telomerase (Figure 11.9) clarified our understanding of how chromosome ends are maintained. Telomerase contains a catalytic part and a built-in RNA template. It attaches to the end of the chromosome, and complementary bases to the RNA template are added on the 3’ end of the DNA strand. Once the 3’ end of the lagging strand template is sufficiently elongated, DNA polymerase can add the nucleotides complementary to the ends of the chromosomes. In this way, the ends of the chromosomes are replicated. In humans, telomerase is typically active in germ cells and adult stem cells; it is not active in adult somatic cells and may be associated with the aging of these cells. Eukaryotic microbes including fungi and protozoans also produce telomerase to maintain chromosomal integrity. For her discovery of telomerase and its action, Elizabeth Blackburn (1948–) received the Nobel Prize for Medicine or Physiology in 2009.
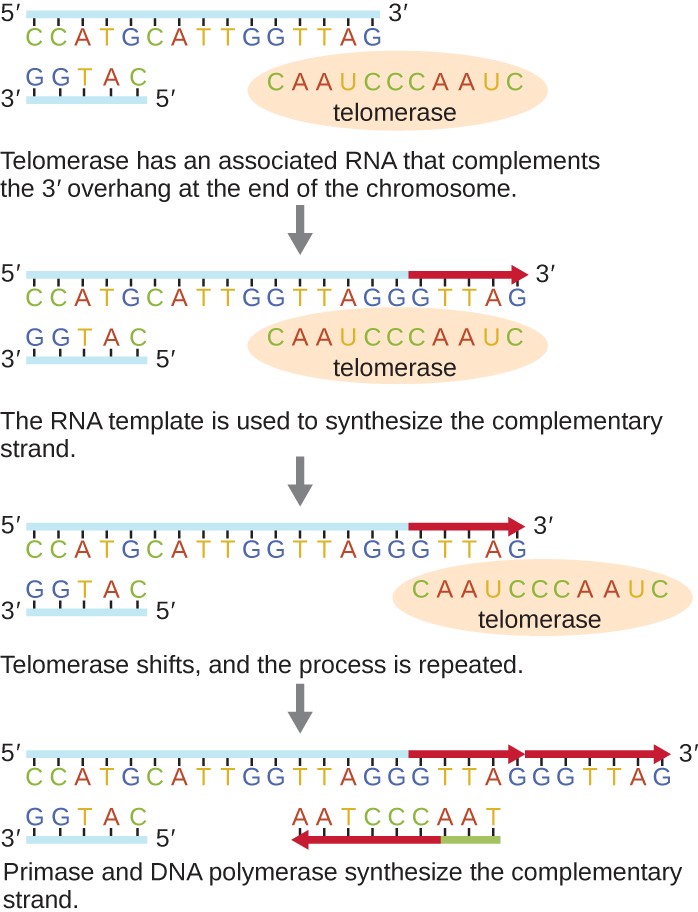
Diagram of telomerase. The top image shows a long strand of DNA with 5’ on the left and 3’ on the right. The complementary strand is much shorter and shows 3’ on the left and 5’ on the right. A circle labeled telomerase contains a complementary strand that matches the 3’ end of the upper strand and also extends past the 3’ end of the top strand. Caption: Telomerase has an associated RNA that complements the 3’ overhang at the end of the chromosome. Next, the top strand of DNA replicates using the overhang of the strand within the telomerase. Caption: The RNA template is used to synthesize the complementary strand. Next, the telomerase moves to the new 3’ end of the top strand. Caption: Telomerase shifts and the process repeats. Finally, The top DNA strand has multiple extensions. RNA primer binds near the 3’ end and builds a new strand of DNA towards the left until it meets up with the existing strand. Caption: Primase and DNA polymerase synthesize the complementary strand.
Comparison of Bacterial and Eukaryotic Replication
| Property | Bacteria | Eukaryotes |
|---|---|---|
| Genome structure | Single circular chromosome | Multiple linear chromosomes |
| Number of origins per chromosome | Single | Multiple |
| Rate of replication | 1000 nucleotides per second | 100 nucleotides per second |
| Telomerase | Not present | Present |
| RNA primer removal | DNA pol I | RNase H |
| Strand elongation | DNA pol III | pol δ, pol ε |
Link to Learning
This animation illustrates the process of DNA replication.
Check Your Understanding
- How does the origin of replication differ between eukaryotes and prokaryotes?
- What polymerase enzymes are responsible for DNA synthesis during eukaryotic replication?
- What is found at the ends of the chromosomes in eukaryotes and why?
DNA Replication of Extrachromosomal Elements: Plasmids and Viruses
To copy their nucleic acids, plasmids and viruses frequently use variations on the pattern of DNA replication described for prokaryote genomes. For more information on the wide range of viral replication strategies, see The Viral Life Cycle.
Rolling Circle Replication
Whereas many bacterial plasmids (see Unique Characteristics of Prokaryotic Cells) replicate by a process similar to that used to copy the bacterial chromosome, other plasmids, several bacteriophages, and some viruses of eukaryotes use rolling circle replication (Figure 11.10). The circular nature of plasmids and the circularization of some viral genomes on infection make this possible. Rolling circle replication begins with the enzymatic nicking of one strand of the double-stranded circular molecule at the double-stranded origin (dso) site. In bacteria, DNA polymerase III binds to the 3’-OH group of the nicked strand and begins to unidirectionally replicate the DNA using the un-nicked strand as a template, displacing the nicked strand as it does so. Completion of DNA replication at the site of the original nick results in full displacement of the nicked strand, which may then recircularize into a single- stranded DNA molecule. RNA primase then synthesizes a primer to initiate DNA replication at the single-stranded origin (sso) site of the single-stranded DNA (ssDNA) molecule, resulting in a double-stranded DNA (dsDNA) molecule identical to the other circular DNA molecule.
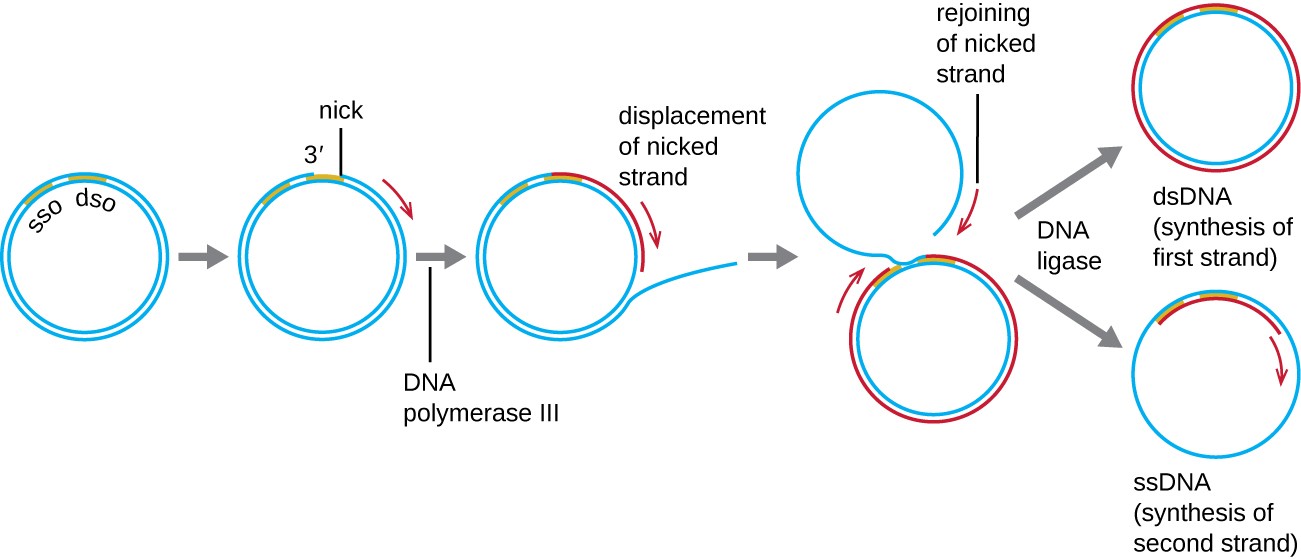
Diagram of DNA replication. A circle of double stranded DNA has a region labeled SSO near a region labeled DSO. A nick forms in DSO and DNA polymerase III begins copying and displacing the nicked strand. This forms a new ring made of an old and a new strand of DNA; the second old strand of DNA is outside of this ring but eventually rejoins the nicked strand. DNA ligase then separates the dsDNA (synthesis of first strand) and the lone ssDNA. The ssDNA then has the second strand synthesized and become a ds DNA as well.
Check Your Understanding
- Is there a lagging strand in rolling circle replication? Why or why not?
