
7.4 – Proteins
Learning Objectives
- Describe the fundamental structure of an amino acid
- Describe the chemical structures of proteins
- Summarize the unique characteristics of proteins
At the beginning of this chapter, a famous experiment was described in which scientists synthesized amino acids under conditions simulating those present on earth long before the evolution of life as we know it. These compounds are capable of bonding together in essentially any number, yielding molecules of essentially any size that possess a wide array of physical and chemical properties and perform numerous functions vital to all organisms. The molecules derived from amino acids can function as structural components of cells and subcellular entities, as sources of nutrients, as atom- and energy-storage reservoirs, and as functional species such as hormones, enzymes, receptors, and transport molecules.
Amino Acids and Peptide Bonds
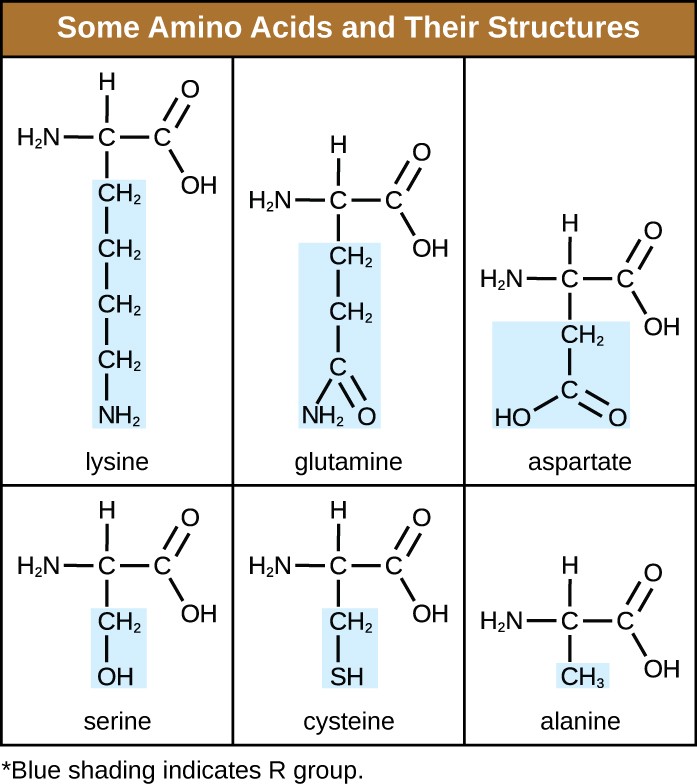
An amino acid is an organic molecule in which a hydrogen atom, a carboxyl group (–COOH), and an amino group (–NH2) are all bonded to the same carbon atom, the so-called α carbon. The fourth group bonded to the α carbon varies among the different amino acids and is called a residue or a side chain, represented in structural formulas by the letter R. A residue is a monomer that results when two or more amino acids combine and remove water molecules. The primary structure of a protein, a peptide chain, is made of amino acid residues. The unique characteristics of the functional groups and R groups allow these components of the amino acids to form hydrogen, ionic, and disulfide bonds, along with polar/nonpolar interactions needed to form secondary, tertiary, and quaternary protein structures. These groups are composed primarily of carbon, hydrogen, oxygen, nitrogen, and sulfur, in the form of hydrocarbons, acids, amides, alcohols, and amines. A few examples illustrating these possibilities are provided in Figure 7.17.
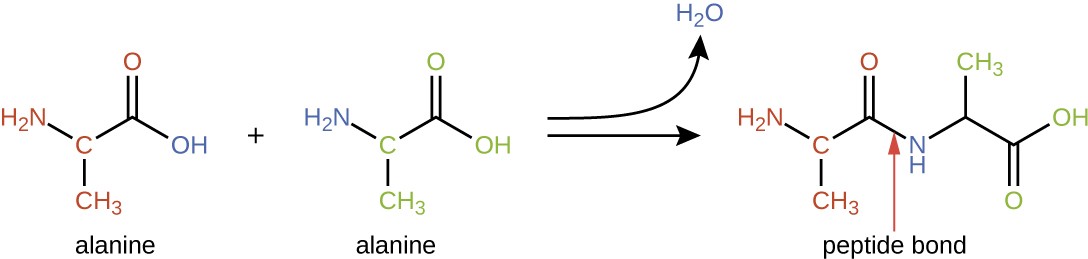
Amino acids may chemically bond together by reaction of the carboxylic acid group of one molecule with the amine group of another. This reaction forms a peptide bond and a water molecule and is another example of dehydration synthesis (Figure 7.18). Molecules formed by chemically linking relatively modest numbers of amino acids (approximately 50 or fewer) are called peptides, and prefixes are often used to specify these numbers: dipeptides (two amino acids), tripeptides (three amino acids), and so forth. More generally, the approximate number of amino acids is designated: oligopeptides are formed by joining up to approximately 20 amino acids, whereas polypeptides are synthesized from up to approximately 50 amino acids. When the number of amino acids linked together becomes very large, or when multiple polypeptides are used as building subunits, the macromolecules that result are called proteins. The continuously variable length (the number of monomers) of these biopolymers, along with the variety of possible R groups on each amino acid, allows for a nearly unlimited diversity in the types of proteins that may be formed.
Check Your Understanding
- How many amino acids are in polypeptides?
Protein Structure
The size (length) and specific amino acid sequence of a protein are major determinants of its shape, and the shape of a protein is critical to its function. For example, in the process of biological nitrogen fixation (see Biogeochemical Cycles), soil microorganisms collectively known as rhizobia symbiotically interact with roots of legume plants such as soybeans, peanuts, or beans to form a novel structure called a nodule on the plant roots. The plant then produces a carrier protein called leghemoglobin, a protein that carries nitrogen or oxygen. Leghemoglobin binds with a very high affinity to its substrate oxygen at a specific region of the protein where the shape and amino acid sequence are appropriate (the active site). If the shape or chemical environment of the active site is altered, even slightly, the substrate may not be able to bind as strongly, or it may not bind at all. Thus, for the protein to be fully active, it must have the appropriate shape for its function.
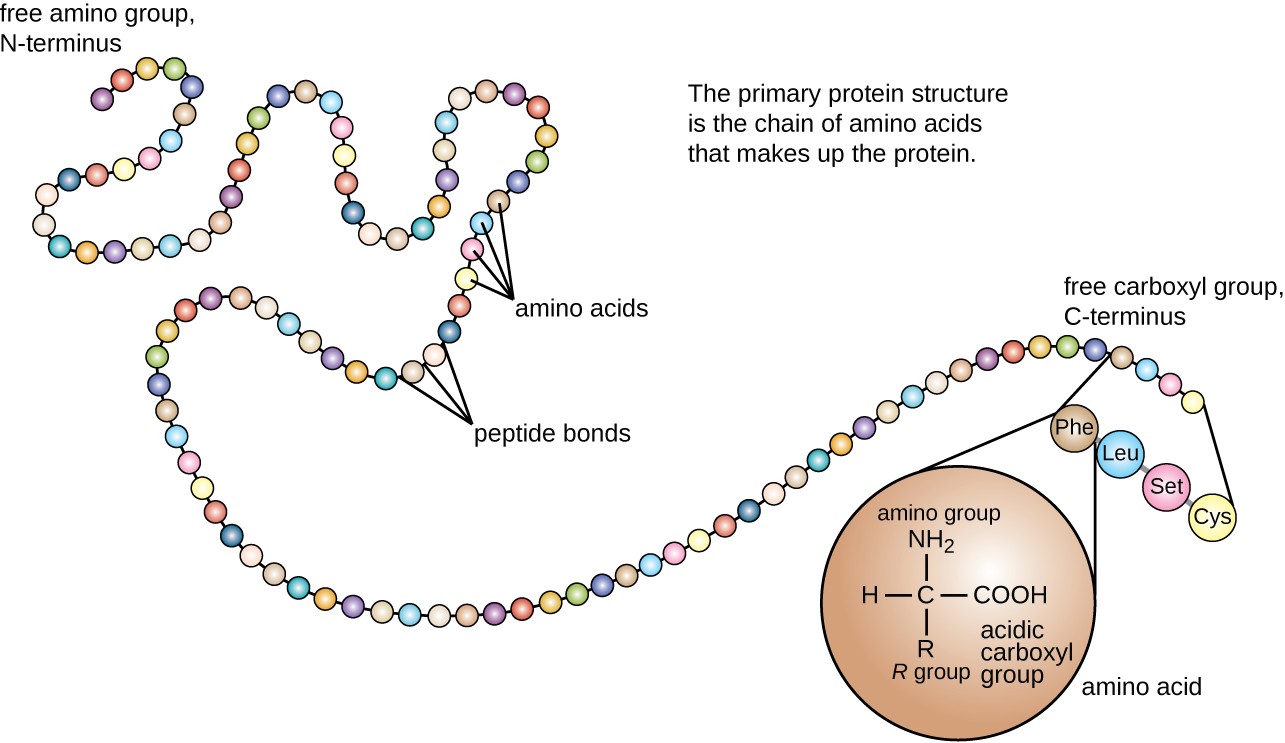
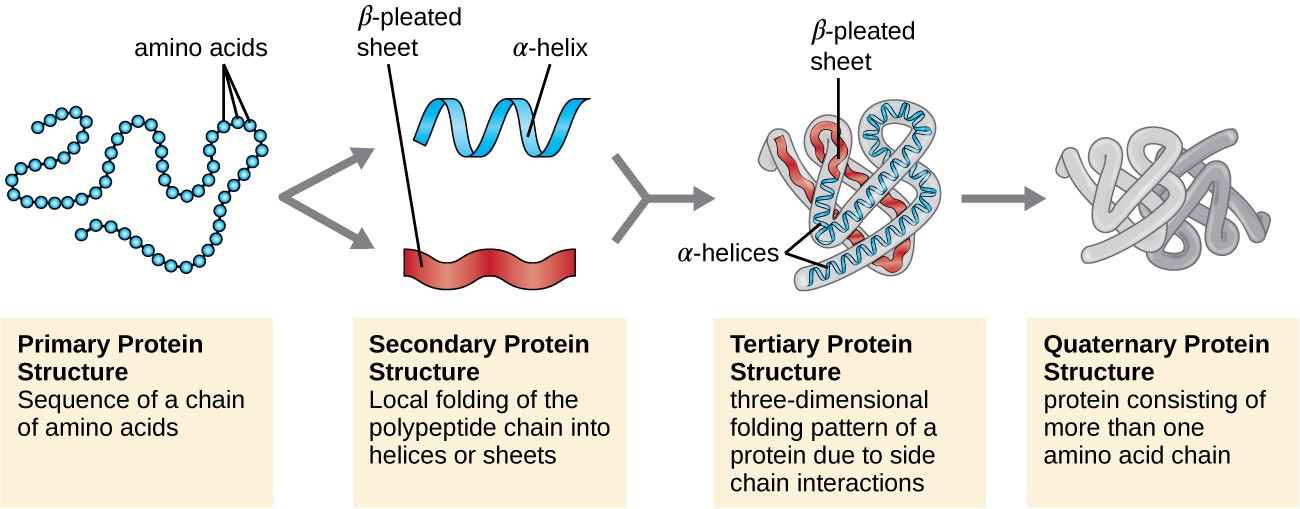
Protein structure is categorized in terms of four levels: primary, secondary, tertiary, and quaternary. The primary structure is simply the sequence of amino acids that make up the polypeptide chain. Figure 7.19 depicts the primary structure of a protein.
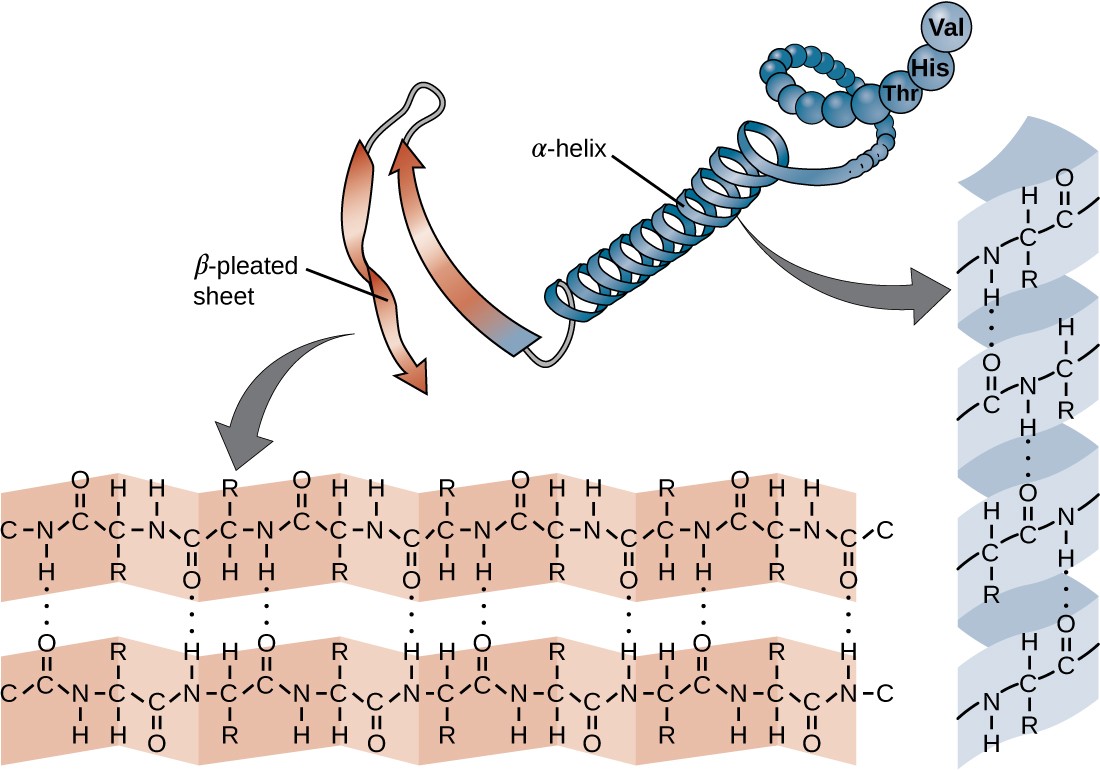
The chain of amino acids that defines a protein’s primary structure is not rigid, but instead is flexible because of the nature of the bonds that hold the amino acids together. When the chain is sufficiently long, hydrogen bonding may occur between amine and carbonyl functional groups within the peptide backbone (excluding the R side group), resulting in localized folding of the polypeptide chain into helices and sheets. These shapes constitute a protein’s secondary structure. The most common secondary structures are the α-helix and β-pleated sheet. In the α-helix structure, the helix is held by hydrogen bonds between the oxygen atom in a carbonyl group of one amino acid and the hydrogen atom of the amino group that is just four amino acid units farther along the chain. In the β-pleated sheet, the pleats are formed by similar hydrogen bonds between continuous sequences of carbonyl and amino groups that are further separated on the backbone of the polypeptide chain (Figure 7.20).
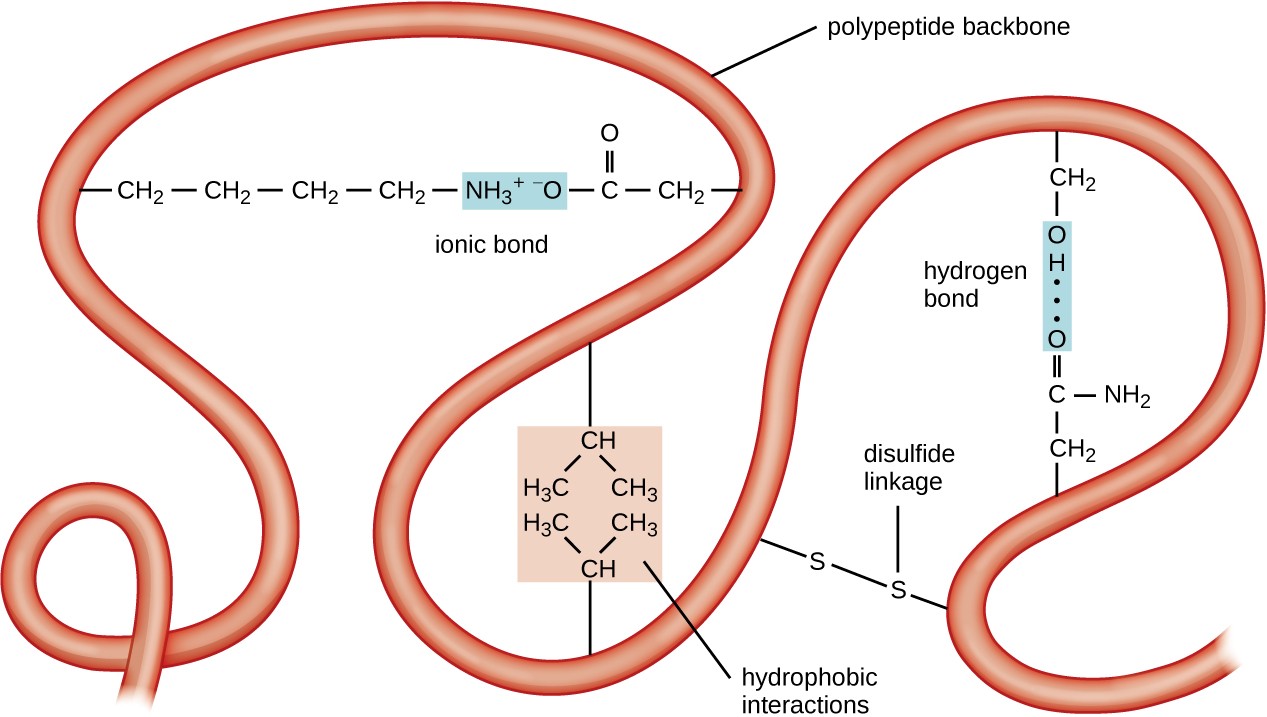
The next level of protein organization is the tertiary structure, which is the large-scale three-dimensional shape of a single polypeptide chain. Tertiary structure is determined by interactions between amino acid residues that are far apart in the chain. A variety of interactions give rise to protein tertiary structure, such as disulfide bridges, which are bonds between the sulfhydryl (–SH) functional groups on amino acid side groups; hydrogen bonds; ionic bonds; and hydrophobic interactions between nonpolar side chains. All these interactions, weak and strong, combine to determine the final three-dimensional shape of the protein and its function (Figure 7.21).
The process by which a polypeptide chain assumes a large-scale, three-dimensional shape is called protein folding. Folded proteins that are fully functional in their normal biological role are said to possess a native structure. When a protein loses its three-dimensional shape, it may no longer be functional. These unfolded proteins are denatured. Denaturation implies the loss of the secondary structure and tertiary structure (and, if present, the quaternary structure) without the loss of the primary structure.
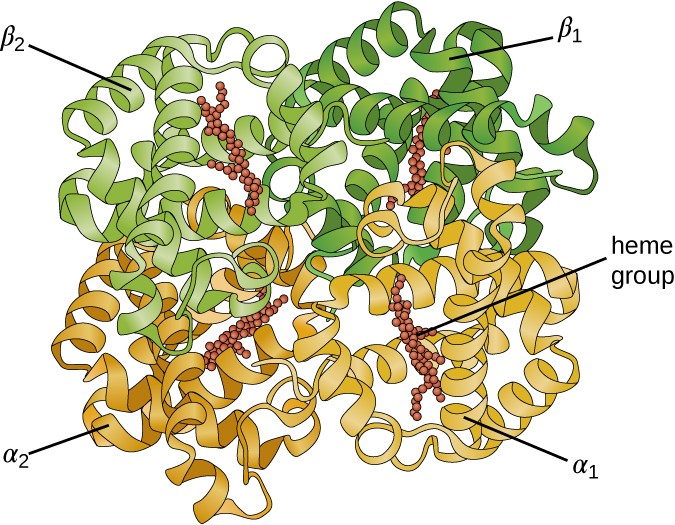
Some proteins are assemblies of several separate polypeptides, also known as protein subunits. These proteins function adequately only when all subunits are present and appropriately configured. The interactions that hold these subunits together constitute the quaternary structure of the protein. The overall quaternary structure is stabilized by relatively weak interactions. Hemoglobin, for example, has a quaternary structure of four globular protein subunits: two α and two β polypeptides, each one containing an iron-based heme (Figure 7.22).
Another important class of proteins is the conjugated proteins that have a nonprotein portion. If the conjugated protein has a carbohydrate attached, it is called a glycoprotein. If it has a lipid attached, it is called a lipoprotein. These proteins are important components of membranes. Figure 7.23 summarizes the four levels of protein structure.
Check Your Understanding
- What can happen if a protein’s primary, secondary, tertiary, or quaternary structure is changed?
Micro Connections
Primary Structure, Dysfunctional Proteins, and Cystic Fibrosis
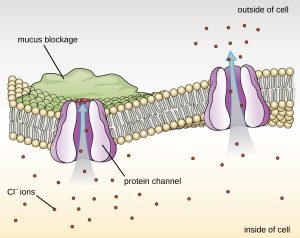
Proteins associated with biological membranes are classified as extrinsic or intrinsic. Extrinsic proteins, also called peripheral proteins, are loosely associated with one side of the membrane. Intrinsic proteins, or integral proteins, are embedded in the membrane and often function as part of transport systems as transmembrane proteins. Cystic fibrosis (CF) is a human genetic disorder caused by a change in the transmembrane protein. It affects mostly the lungs but may also affect the pancreas, liver, kidneys, and intestine. CF is caused by a loss of the amino acid phenylalanine in a cystic fibrosis transmembrane protein (CFTR). The loss of one amino acid changes the primary structure of a protein that normally helps transport salt and water in and out of cells (Figure 7.24).
The change in the primary structure prevents the protein from functioning properly, which causes the body to produce unusually thick mucus that clogs the lungs and leads to the accumulation of sticky mucus. The mucus obstructs the pancreas and stops natural enzymes from helping the body break down food and absorb vital nutrients.
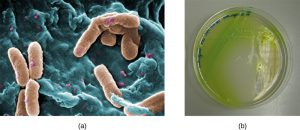
In the lungs of individuals with cystic fibrosis, the altered mucus provides an environment where bacteria can thrive. This colonization leads to the formation of biofilms in the small airways of the lungs. The most common pathogens found in the lungs of patients with cystic fibrosis are Pseudomonas aeruginosa (Figure 7.25) and Burkholderia cepacia. Pseudomonas differentiates within the biofilm in the lung and forms large colonies, called “mucoid” Pseudomonas. The colonies have a unique pigmentation that shows up in laboratory tests (Figure 7.25) and provides physicians with the first clue that the patient has CF (such colonies are rare in healthy individuals).
Link to Learning
For more information about cystic fibrosis, visit the Cystic Fibrosis Foundation website.
