
Database and Lost Update Problem
Database
Purpose?
To help people keep track of things!
What is a Database?
A self Describing collection of integrated records.
What are the components of a Database?
Tables, Rows or Records, Fields or Columns, Bytes or Characters = Values, Meta Data
- Course Title?
- Underlie most applications you will work on.
- Ubiquitous in Organizations.
- Ultimately used to organize inputs and outputs of processes.
- Increasing demand for with IOT.
- Need for ever more data processing power.
- Structured or Unstructured
Fields – Fields are categories for data, and are specified for accepted field entries, such as INT, CHAR, STRING, etc. These are sometimes referred to as columns.
Record – Each row in the table is also known as a record.
Character – Each letter or number entered into a field for a record is a character, or “byte”.
Lets think about a database that keeps tracks of course registrations at your university.
First we would need a students table containing information about students. One row per student, which might look like the table below.
Field names are across the top and there is a primary key. That is a unique identifier that will be unique for each row or record in the database. In this case it is STUDENT_ID. Sometimes in a data diagram these are annotated with a small key icon. Another way to identify keys is with a line showing the common field in another table, which we will see later.

(Note the ellipsis at the bottom means there are more records in this table than what are shown here, the ellipsis at top right of the screen signifies that there are likely more fields in this table than what we are showing here.)
We will also need a table showing the title of the courses available to take:

But this is not a full listing of what a student an enroll in as each course may have different sections taught by different professors so a course section table will be required to get us to the detailed transaction.

Not this is a course section listing so a given course can occur more than once if it has more than one section. The primary key here then is called COURSE_INDX. Can you see any relationship between the Student and the Course List tables? Not yet!
That would be our transaction table, showing students enrolled in each section of the course and might look like this:

We can see that a student enrolled in a section of the class is one record. Now we can see a relationship between Student and Course. In the case of enrollment we might consider a student enrolling in a section of a course in one semester to be an individual transaction. If we were to aggregate this data, all the class enrollments for the semester would be the total transactions or the enrollment for the term.
Looking at the transaction table alone it does not tell us what the student’s name is or who is teaching the class, or where it is located. Those are descriptive data stored in the student and course table and we would need to access or join the course and student tables to retrieve them for a report or dashboard. Since a student can enroll in more than one class, and many students can enroll in the same class. Storing the student and course names in this table would require we store a lot of duplicate data in the enrollment table. As we plan to use a relational database it is simpler and cleaner to store the student name once in the student table and the same with course title. In this way an update to the enrollment table is simple, quicker, and uses less resources compute resources. This also allows us to change a course title in one place and have it reflected all through out the application. This is database normalization. We remove the data that is not changing as often from the transaction table (which is changing often during the enrollment period) and store in a descriptive table where it can be changed if needed but is not part of the transaction when a student enrolls in a class. We will see later in the course that the transaction table may be referred to as the Fact table and the descriptive tables as Dimension tables. If we add a faculty table we can connect them all in a diagram like the one below:
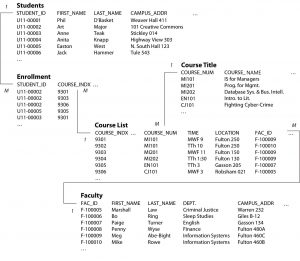
A Simplified Relational Database for a University Course Registration System
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License
The diagram above is a database schema, it shows us the tables and fields and the relationships between them. Note the lines connecting the keys in the tables to show how they are related. Fac_ID is the primary key in the Faculty table above and a foreign key in the Course Title table. The line shows us how the are connected. The M and 1 on either end of the connecting line is one way of showing us that 1 Faculty member might exist in multiple rows of the course table (if the member is teaching more than one section or course.) This relationship could be referred to as “One to Many” meaning one Faculty member can exist many or multiple times (really more than once) in the course table. In reverse you could say many (or multiple) course/section listings could be taught by a single faculty member so the relationship in reverse is “Many to One”.
What would the relationship for Student to course be ? How about Course list to Course Title?
Relational Database Components
Primary Key – specific choice of a minimal set of attributes (columns) that uniquely specify a row or record in a relational table. Informally, a primary key is “which attributes identify a record”, and in many (simple) cases are simply a single attribute: a unique id.
Foreign Key – a column or group of columns in a relational database table that provides a link between data in two tables. It acts as a cross-reference between tables because it references the primary key of another table, thereby establishing a link between them.
SQL Basics
When working with rows or records in tables there are four primary SQL commands used: Select, Update, Insert, Delete, Create.
SELECT is basically a filtered request to return records from a table based on criteria, if used with a Join, data from more than one table can be returned. Join appends the fields from one table to the fields from another. This is covered in more detail in most Database classes. See below for a brief example of a Select statement without a join:
Select * from [Course List] would return all rows and fields from the table Course List. The * is a default which means all fields in this case
If we add a condition
Select * from [Course List] where COURSE_INDX > 9400 (assuming COURSE_INDX is numeric) would return the full rows for the rows where COURSE_INDX is 9304, 9305,and 9306
If we want to select only certain fields
Select FAC_ID from [Course List] where COURSE_INDX > 9400 would return F-100009, F-100007, F-100005
INSERT is used to add new rows to a table. The syntax requires us to specify the fields we want t o update followed by the values for each field listed. An example might look something like the following:
INSERT into Students ( STUDENT_ID, FIRST_NAME, LAST_NAME, CAMPUS_ADDR )
Values (‘U11-0007’, ‘Frank’, ‘N-Furter’, ‘Rocky Way’) ;
DELETE is used to remove records from a table or tables.
UPDATE is used to change or update the data in existing rows in a table(s)
Lastly lets take a quick look look at a Select with a Join
Select STUDENT_ID, FIRST_NAME, LAST_NAME from Enrollment Left Outer Join Students
on Enrollment.STUDENT_ID = Students.STUDENT_ID
where COURSE_INDX > 9301
This would return
U11-00002 Art Major
U11-00002 Art Major
U11-00005 Easton West
What would the Join look like to if you wanted it to return the student_ID, Student First and Last name, course number, and course name?
Relational Meta Data
DBMS – Database Management System
Collection of:
- Forms – View Data – CRUD – Create, Read, Update, Delete
- Reports – Structured Presentation of data using sorting, grouping, filters, and other operations
- Queries – Search based on values provided by the user
That serve as an intermediary between users and database.
Multi Tier – Where is the Business Logic?

Relational Problem
Multiuser Processing
Many applications involve multiple users processing the same database. Multiuser processing can pose unique problems that you should know about. To understand the nature of those problems, consider the following scenario, which could occur on either a thin-client or traditional client server application.
Buddy and Annie are two separate customers perusing a ticket vendor’s Web site. They both decide they want to buy the last two tickets in section A row 6, (seats 113 and 115) which appear to be available. Annie uses her browser to access the site and sees that two seats are available and places both of them in her shopping cart. When Annie opened the order form, she invoked an application program on the vendor’s servers that read a database to find that two are available. Before she checks out, she takes a moment to verify with her friend that they still want to go.
Meanwhile, Buddy uses his browser and also sees the two tickets available because his browser activates that same application that reads the database and finds (because Annie has not yet checked out) that two are available. He places both in his cart and checks out.
Meanwhile, Annie decides to buy both, so she checks out. Clearly, we have a problem. Both Annie and Buddy have purchased the same two seats in Section A row 6. One of them is going to be disappointed.
This is called the Lost-update problem, and exemplifies one of the special characteristics of multi-user database processing. To solve this problem some type of locking must be implemented while Annie is deciding. You have likely seen this if you buy tickets on line. Your browser application might tell you that you have the tickets in your cart and you have 5 minutes to check out or they will be released to other users. Another way to think of this principal is that the inventory has been allocated to Annie. It has not been sold yet but has been allocated to Annie’s order. If Annie decides not purchase the tickets than they must be deallocated, or put back in available inventory. We will talk more about this later in the course.
At this point, just be aware of that data conflicts or inconsistencies can arise with multi-user processing of data and your application design must take this into account and provide the proper safeguards to assure your transactions will flow correctly.
